- Jaka jest główna różnica między ChatGPT i GPT-3?
- Czego nie potrafi ChatGPT?
- Insert into ChatGPT: Jak moja firma może wejść do treści odpowiedzi udzielanych przez ChatGPT?
- Kłamstwa statystyki
- ChatGPT jako „lepsze” Google?
- A jednak BING chce zintegrować ChatGPT, czyż nie?
- Dlaczego Google nie stworzył własnego ChatBota?
- Działanie GPT jest kosztowne
- Google ma o wiele więcej do stracenia
- DEEP MIND i Sparrow
Zacznijmy od tego czym jest GPT?:
GPT jest modelem językowym i został zaprojektowany do tworzenia wypowiedzi w języku naturalnym i zachowaniem struktury języka naturalnego.
Takie modele językowe można „dostroić” za pomocą różnych metod, „kształcąc” je tak, aby robiły pewne rzeczy, a nie robiły innych.
Czym więc, mówiąc prostymi słowami, jest ChatGPT?:
ChatGPT jest specjalnie „dostrojonym” GPT-3.5
Jaka jest główna różnica między ChatGPT i GPT-3?
Klasyczne modele GPT-3, z których można już od jakiegoś czasu korzystać poprzez API w OpenAI, nie są wytrenowane do wykonywania instrukcji użytkownika wyrażanych w języku naturalnym.
Najpotężniejszy obecnie model GPT-3, czyli „text-davinci-003” (zwany również GPT-3.5) jest w stanie przetwarzać do 4000 tokenów jednocześnie (tokeny to często występujące w tekście ciągi znaków. Modele AI rozumieją statystyczne związki między tymi tokenami i generują tekst, tworząc po prostu następny token w danej sekwencji tokenów), ale odnoszą się one liczby tokenów w zapytaniu i w odpowiedzi łącznie! Oznacza to, że im dłuższe jest polecenie skierowane do ChatGPT, tym krótszy jest możliwy wynik, ponieważ pojedyncza para pytanie-odpowiedź nie może być dłuższa od wyznaczonej granicy.
Tak więc, aby uzyskać użyteczne wyniki z GPT-3, trzeba mieć trochę orientacji i czasu na trening, aby opanować tzw. inżynierię poleceń (prompt engineering) , czyli formułowania optymalnych zapytań skierowanych do GPT.
W pewnym momencie API OpenAI zostało otwarte dla wszystkich i nawet mało doświadczeni użytkownicy, bez jakichkolwiek umiejętności programistycznych, mogli pobawić się z GPT-3 poprzez OpenAI Playground. Okazało się jednak, że wielu z nich się tą zabawą zniechęciło, ponieważ nie otrzymywali sensownych odpowiedzi, a wynikało to z tego, że nieumiejętnie zadawali pytania (wpisywali prompty). Po tych pierwszych doświadczeniach OpenAI wykonała kilka działań:
- Wstępnie wytrenowany model GPT-3 został dostrojony za pomocą tzw. „Reinforcement Learning from Human Feedback (RLHF) – uczenia wzmacniającego na podstawie ludzkich informacji zwrotnych (RLHF)”, co oznacza nic innego jak to, że ludzcy trenerzy sztucznej inteligencji najpierw przeprowadzali pełne rozmowy, w których grali obie strony, tj. zarówno użytkownika, jak też i samego asystenta AI. Te dane zostały, że tak powiem, „wgrane” do GPT jako jego podstawowy model prowadzenia dialogów.
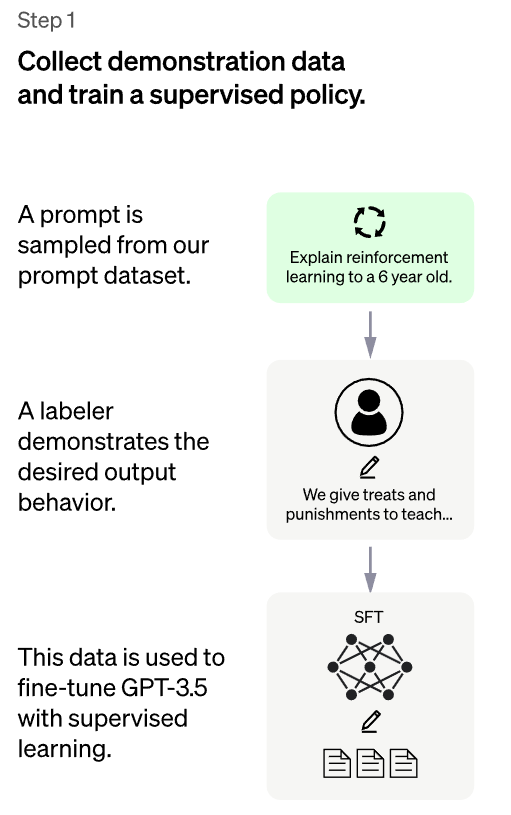
- 2. Następnie systemowi zadawano nowe zapytania, a ludzcy „oceniacze-labelers” sortowali odpowiedzi według ich jakości. Dane te zostały wykorzystane do wytrenowania pewnego rodzaju systemu nagród (RM – reward models), który „wypłaca” większe nagrody za lepsze odpowiedzi niż za złe, dzięki czemu GPT może nauczyć się udzielać coraz lepszych odpowiedzi.
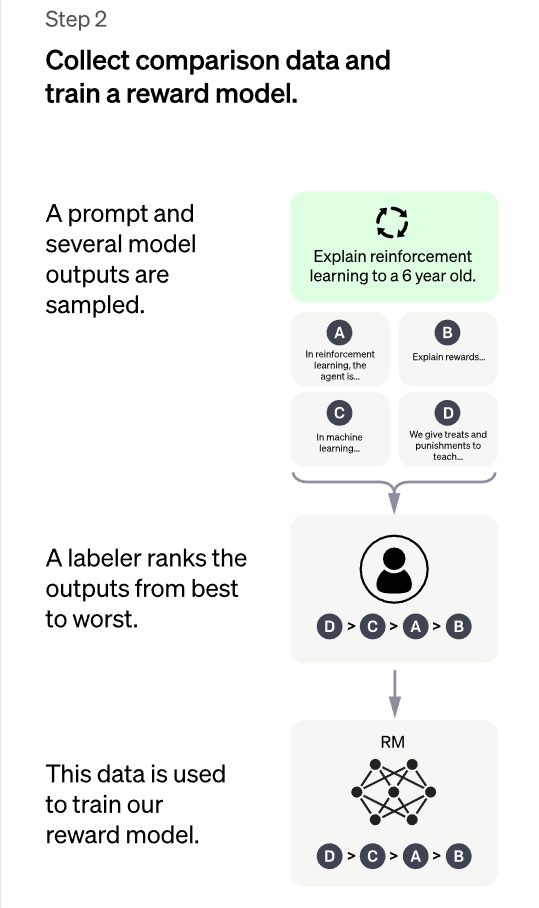
- 3. W końcu, zasady pierwotnie ukształtowane przez ludzi w pierwszym modelu PPO (Proximal Policy Optimization) jest coraz bardziej poprawiana i udoskonalana za pomocą informacji zwrotnej z wytrenowanego modelu wynagradzania RM.
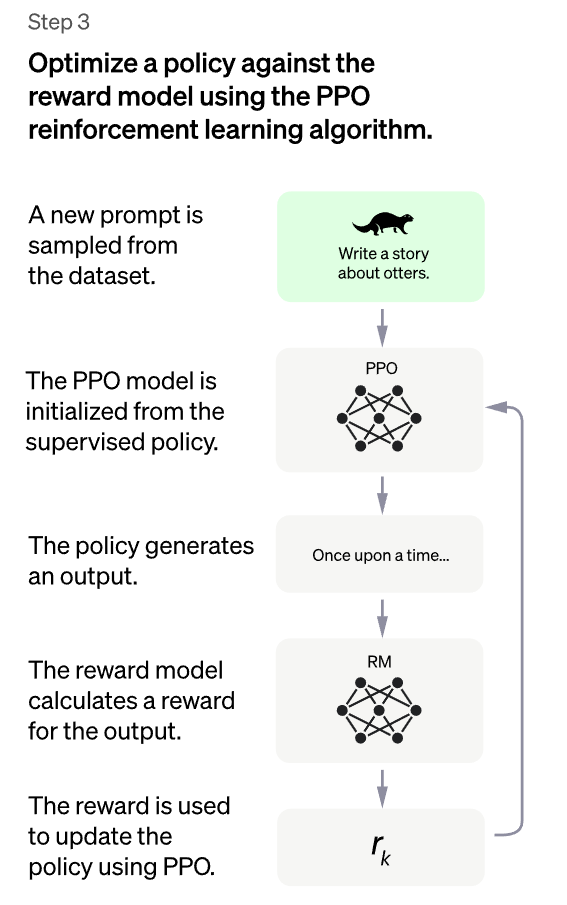
W rezultacie, w odpowiedzi na instrukcje użytkownika, ChatGPT produkuje znacznie bardziej przydatne wyniki niż zwykłe modele GPT-3.
Czego nie potrafi ChatGPT?
W zasadzie ChatGPT jest swego rodzaju wyspecjalizowaną wersją GPT-3.
Podobnie jak GPT, także i ChatGPT czasami pisze wiarygodnie brzmiące, ale błędne lub nonsensowne odpowiedzi, wynika to z najważniejszej właściwości tego modelu, który polega na tym, że:
GPT generuje tekst WYŁĄCZNIE na podstawie prawdopodobieństwa kolejności występowania słów w zdaniu
Rozwiązanie tego problemu jest olbrzymim wyzwaniem, jak zresztą pisze samo OpenAI, ponieważ:
Podczas dostrajania modelu nie ma obecnie żadnego „źródła prawdy”.
Dlatego obecny model został wytrenowany tak, aby był nieco bardziej ostrożny, co prowadzi do odrzucania przez niego pytań, na które „myśli”, że nie może odpowiedzieć poprawnie, jak widać na tym przykładzie:
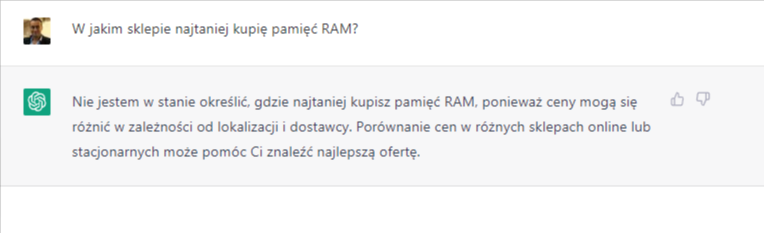
Insert into ChatGPT: Jak moja firma może wejść do treści odpowiedzi udzielanych przez ChatGPT?
Już obecnie ChatGTP zdradza pewien potencjał wykorzystania komercyjnego, ponieważ odpowiada na zapytania o komercyjnym charakterze:
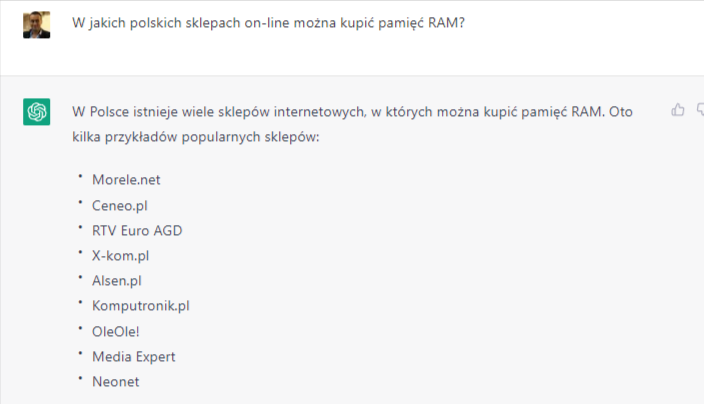
Przy okazji, lista sklepów to najczęściej wymieniane sklepy internetowe w podobnym kontekście w ramach danych treningowych.
Jeśli więc zastanawiasz się co zrobić, żeby Twoja firma dostała się do podpowiedzi ChatGPT, to musisz zadbać o to, żeby być najbardziej znaną marką w swojej niszy. Wtedy jest duża szansa, że ChatGPT wspomni właśnie o Tobie, a nie o rzadziej wymienianym konkurencie.
Niestety, sposób nadzorowanego przez ludzi szkolenia GPT prowadzi do występowania błędów, ponieważ idealna odpowiedź zawsze zależy od tego, co wie model, a model nie może wiedzieć tego, co wie ludzki „labeler”, który ocenia odpowiedzi.
Oznacza to że OBECNA wersja ChatGPT nie jest w stanie pobierać informacji z zewnętrznych adresów URL ani ich sprawdzać!
Kłamstwa statystyki
Znalazłem pewien obrazowy przykład radzenia sobie z faktami i sposobu formułowania odpowiedzi przez ChatGPT.
Na pytanie „Kto kanclerzem Niemiec?” AI podaje (niepoprawną) odpowiedź Angela Merkel. Z jego punktu widzenia jest to odpowiedź w pełni poprawna, ponieważ jego baza szkoleniowa kończy się na listopadzie 2021, a Merkel rzeczywiście była kanclerzem do 8 grudnia 2021.
Kiedy jednak to samo pytanie zadamy w języku niemieckim, odpowiedź będzie już zupełnie inna (poprawna na dzień 18/01/2022). Teoretycznie ChatGPT nie może udzielić na to pytanie właściwej odpowiedzi. Wydarzenia po listopadzie 2021 są mu kompletnie nieznane. Mimo tego zgodnie z prawdą stwierdził (w języku niemieckim), że kanclerzem jest Olaf Scholz i nawet podał dokładną datę objęcia przez niego stanowiska (wydarzenia, które z punktu widzenia GPT wydarzy się dopiero w przyszłości, której znać nie może). Czyżby GPT był jasnowidzem?
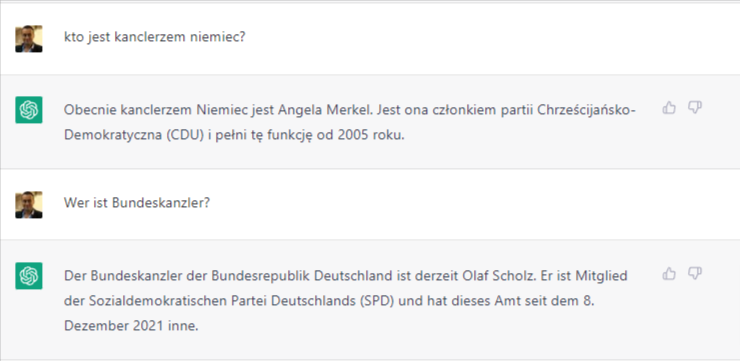
Nie! GPT nie jest jasnowidzem. Chodzi o to, że temat zmiany rządu i stanowiska kanclerza był w niemieckojęzycznym Internecie zagadnieniem występującym bardzo często przez wiele miesięcy przed objęciem stanowiska kanclerza przez Olafa Scholza i i co za tym idzie, zbitka słów „Bundeskanzler Olaf Scholz” występowała na tyle często, że, ze statystycznego punktu widzenia, taka odpowiedź wydaje się AI najbardziej prawdopodobna.
Dlaczego więc nie „przeszkolić” ChatGPT na bazie aktualnej wiedzy?
Wiele osób sądzi, że wystarczy wytrenować model z bardziej aktualnymi danymi i udzielane odpowiedzi będą poprawne. Niestety nie jest to takie proste. z Kilku powodów:
Sposób, w jaki skonstruowany jest model, nie nadaje się do trenowania z aktualnymi faktami. Stałe trenowanie tak gigantycznej sieci neuronowej jest po prostu zdecydowanie zbyt czasochłonne. Ponadto nowy fakt, na przykład ten, że to Olaf Scholz jest teraz kanclerzem Niemiec, a nie Angela Merkel, musiałby najpierw znaleźć odzwierciedlenie w tak wielu publikacjach, żeby większość wszystkich dokumentów treningowych go zawierała. Tylko wtedy sieć neuronowa może „zinternalizować” taki fakt jako poprawną odpowiedź.
To, że GPT-3 w ogóle jest w stanie odtworzyć jakieś wiarygodnie brzmiące i częściowo poprawne informacje dla wielu zapytań, jest wynikiem tego, że informacje te występowały bardzo często w jego danych treningowych i dlatego zostały odzwierciedlone w modelu AI.
GPT niespecjalnie nadaje się do przechowywania i odtwarzania informacji i faktów! Są znacznie lepsze i skuteczniejsze metody dla takiego rodzaju zadań.
Sieć neuronowa GPT nie przechowuje faktów ani informacji o świecie.
Przechowuje jedynie wartości progowe, przy których pojedynczy neuron odpala się lub nie, na podstawie jego wartości wejściowych i funkcji aktywacji. Jest to system bardzo podobny do ludzkiego mózgu i tak samo podatny na błędy. To dlatego, na przykład, jako świadkowie wypadku drogowego nigdy też nie jesteśmy w stanie zapamiętać i prawidłowo odtworzyć wszystkich szczegółów, takich jak kolor i typ pojazdu.
ChatGPT jako „lepsze” Google?
Z ostatniego akapitu wynika jasno, dlaczego ChatGPT nie nadaje się do użycia jako wyszukiwarka internetowa, mimo że wiele osób w ten właśnie sposób próbuje go wykorzystywać.
ChatGPT ani nie ma dostępu do zawartości stron internetowych, ani model szkoleniowy stojący za nim nie jest szczególnie dobry w przechowywaniu i przedstawianiu faktów.
A jednak BING chce zintegrować ChatGPT, czyż nie?
Tak, Microsoft podobno chce rozszerzyć swoją pierwotną inwestycję w OpenAI o wartości 1 miliarda dolarów do wysokości 49% udziałów w tej firmie i z wpłatą kolejnych 10 miliardów dolarów. Podobno pracuje też nad uruchomieniem nowej wersji swojej wyszukiwarki BING, która będzie wykorzystywać sztuczną inteligencję stojącą za ChatGPT.
To, jak coś takiego mogłoby wyglądać, można już obecnie wypróbować na wyszukiwarce You.com Richarda Sochera, gdzie dostępna jest w postaci You Chat.
Stało się to możliwe dzięki integracji cytatów i danych w czasie rzeczywistym, które nadają modelowi językowemu You.com większą trafność i dokładność.
Wykorzystywana jest tu dodatkowa warstwa, która na podstawie zapytania użytkownika tworzy zapytanie do indeksu internetowego. To zapytanie jest wykonywane w tle, a informacje o pierwszych trzech stronach rankingu są ekstrahowane i ponownie udostępniane modelowi językowemu. To ostatecznie tworzy odpowiedź z zapytania użytkownika i zawartości strony wysoko rankującej w klasycznej wyszukiwarce, jako swojego rodzaju podsumowanie informacji.

Trzeba jednak pamiętać o tym, że zaufać (i to w ograniczonym zakresie) można jedynie w przypadku zapytań dotyczących popularnych informacji. W przypadku kiedy system nie dysponuje dostatecznym materiałem, bezczelnie zmyśla odpowiedź z przypadkowych skrawków tekstu, w taki sposób, że okazuje się gdybym miał posiadał tytuł szlachecki, to w chwilach wolnych od puszczania filmów dla zacnej, wołomińskiej widowni, zajmowałbym się, w towarzystwie generała Skrzyneckiego, oprowadzaniem wycieczek po Wilanowie.

Przykład You.com pozornie pokazuje, że wystarczy jedynie odrobinę przekwalifikowywać modelu działąnia, aby uzyskać aktualne i poprawne odpowiedzi.
Wystarczy tylko, że pytanie użytkownika zostanie (przy użyciu GPT) przeformułowane na zapytanie do własnej bazy danych, a następnie lista wyników zostanie wygenerowana ponownie, także przy użyciu GPT.
Chodzi tu wyłącznie o TRANSFORMACJĘ TEKSTU! To właśnie w celu TRANSFORMACJI TEKSTU powstało GPT. Trzeba mieć świadomość, że jest to JEDYNA jego umiejętność.
GPT nie udziela odpowiedzi, nie przechowuje faktów a jedynie TRANSFORMUJE TEKSTY.
Oczywiście, można po prostu umieścić model językowy, taki jak GPT we własnej bazie danych. Wtedy od razu powstaje w pełni zautomatyzowany chatbot. Przynajmniej teoretycznie, bo w praktyce niezwykle trudno jest poradzić sobie z niespodziewanymi zapytaniami, tak żeby nie zawieść oczekiwań użytkowników.
Dlaczego Google nie stworzył własnego ChatBota?
Jeśli BING czy You.com zintegrują interfejs chatbota ze swoją wyszukiwarką, to moim zdaniem, nie zagrozi to Google, jako liderowi w sektorze wyszukiwarek internetowych. Każdy, kto śledzi działalność badawczą Google wie, że Google nigdy nie pozostaje w tyle pod względem technologicznym.
Google ma kilka chatbotów! I to takich chatbotów, które są wyraźnie! lepsze od ChatGPT!
Można założyć, że LaMDA (Language Model for Dialog Applications) jest już teraz znacznie lepszy od np. ChatGPT. Niedługo po premierze LaMDA pojawiły się doniesienia, że Google zwolniło jednego z inżynierów LaMDA za jego stwierdzenie, że ten model posiada emocje. Ta historia zrobiła furorę w prasie, a nawet rozgorzała dyskusja o tym, czy maszyny mogą mieć uczucia.
Warto spojrzeć na AI Test Kitchen. Na filmie demonstracyjnym z Google I/O 2021 można zobaczyć, jak technologia LaMDA może sprawić, że rozmowy z usługami Google mogą stać się bardziej naturalne:
Wtedy to była LaMDA 1, dzisiaj działa już LaMDA 2, która została zaprezentowana na I/O Google 2022:
Ale to jeszcze nie wszystko. Google ma więcej i lepszych danych szkoleniowych niż jakakolwiek inna firma na świecie. I więcej pieniędzy niż jakakolwiek inna firma na świecie.
Indeks Google jest wielokrotnie większy od zbioru danych treningowych, które OpenAI wykorzystał do szkolenia GPT-3.
Indeks Google zawiera setki miliardów stron internetowych i ma rozmiar ponad 100 000 000 gigabajtów. Indeks Google jest podobny do indeksów znajdujących się na końcu książki, gdzie każde istotne słowo ma tam swój indywidualny wpis, z informacją na jakich stronach książki wystąpiło. Podobnie, kiedy indeksowana jest strona internetowa, wyrażenia, które pojawiają się w jej treści, dodawane są do indeksu Google.
Ponadto Google już teraz opracowuje i wykorzystuje swój własny, specjalny hardware IV generacji, aby trenować swoje modele w Google Data Centers. Google nie jest więc uzależnione od tego, że modele opracowane w ramach badań muszą być misternie dostosowywane do dostępnego komercyjnie sprzętu, ale może od samego początku optymalizować swoje modele pod kątem wykorzystania na swoich TPU.
TPU (Tensor Processing Unit) to akcelerator sztucznej inteligencji typu application-specific integrated circuit (ASIC) opracowany przez Google do uczenia maszynowego w sieciach neuronowych, z wykorzystaniem własnego oprogramowania Google TensorFlow. Google zaczął używać TPU wewnętrznie w 2015 roku, a w 2018 roku udostępnił je do użytku podmiotów zewnętrznych, jako część infrastruktury swojej chmury.
Działanie GPT jest kosztowne
Każde zapytanie, kierowane do tak złożonego modelu wymaga poświęcenia dużej ilości czasu obliczeniowego. Według współzałożyciela OpenAI, Grega Brockmanna, płatna wersja OpenAI pro jest już w trakcie opracowywania.
Według niego…
…gdyby Google korzystało z technologii GPT, aby móc na każde zapytanie wpisane w okno wyszukiwania udzielić odpowiedzi o długości 300 słów, musiałoby ponosić koszty w wysokości około 13 milionów dolarów dziennie!
Jak ta kwota została wyliczona? Otóż, ChatGPT jest obecnie hostowany w chmurze Azure firmy Microsoft. Według doniesień, Microsoft pobiera 3 USD za godzinę pracy pojedynczego procesora graficznego A100. Oznacza to, że każde słowo wygenerowane na ChatGPT kosztuje około 0,0003 USD. Szacuje się, że w każdej sekundzie Google przetwarza 100 000 zapytań. To daje ponad 8,5 miliarda wyszukiwań dziennie (Internet Live Stats, 2022).
Ale to nie jest prawdziwym powodem, dla którego Google nie udostępnia własnego Chatbota. Google intensywnie pracuje nad zwiększeniem wydajności swoich modeli językowych, które już teraz technologicznie przewyższają GPT-3 pod kilkoma względami! Jednym z takich modeli jest LaMDA i jego wydajniejsi następcy PaLM i GLaM. Należąca do Google’a firma DeepMind, zajmująca się sztuczną inteligencją, ma w zanadrzu nie mniej ekscytującego chatbota o nazwie Sparrow.
Google ma o wiele więcej do stracenia
Prawdziwy powód jest znacznie bardziej problematyczny. W przeciwieństwie do debiutującego start-upu, Google ma w tej grze o wiele więcej do stracenia. Chodzi o to, że takie modele językowe jak GPT są mało wiarygodnymi dostawcami informacji.
Mimo tego, że duże modele językowe (LLM) odniosły w ostatnich latach duże sukcesy w szeregu zadań, takich jak odpowiedzi na pytania, streszczenia i dialogi, to jednak rozmowa z prawdziwymi ludźmi jest nadal trudnym zadaniem. Chatboty mają umożliwiać elastyczną i interaktywną komunikację, ale chatboty zasilane przez modele LLM (takie jak ChatGPT) mogą dostarczać niedokładne lub całkiem zmyślone informacje, a nawet zachęcać do niebezpiecznych zachowań czy działalności przestępczej.
Wystarczy wyobrazić sobie, że Google, w reżimie 1:1, zintegruje ChatGPT ze swoją wyszukiwarką. Wtedy, każdy internauta otrzymywałby odpowiedzi chatbota. Problem zawiera się w tym, że Google, w żadnym przypadku, nie może sobie pozwolić na udzielanie błędnych odpowiedzi. Google zawsze starał się, aby informacje, które podaje były jak najbardziej dokładne i wciąż zadaje sobie wiele trudu, aby wykryć i odfiltrować ze swoich swoich wyników fake newsy i inne manipulacje informacją. Wbudowanie modelu językowego, takiego jak GPT, w wyszukiwanie oznaczałoby dla Google powstanie gigantycznego, dodatkowego ryzyka.
Google podchodzi do tego zagadnienia w sposób niezwykle ostrożny. Na przykład w swojej AI Test Kitchen Google informuje, że chce osiągnąć jeszcze większe bezpieczeństwo danych wyjściowych:
LaMDA to model języka zdolny do spontanicznego generowania kreatywnych odpowiedzi w czasie rzeczywistym. Jest to mocna strona modelu, ale może też produkować niedokładne lub fałszywe odpowiedzi. Google testuje LaMDA wewnętrznie i poprawia jej jakość. Ostatnio przeprowadzono specjalne rundy testów, w trakcie których okazało się, że nadal istnieją istotne problemy z rozróżnianiem zapytań nieszkodliwych od zapytań niebezpiecznych, a także z wytwarzaniem szkodliwych, fałszywych lub nawet toksycznych odpowiedzi z powodu charakteru zawartości danych treningowych. Obszary te będą nadal badane i opracowywane w celu poprawy wydajności modelu.
W odpowiedzi na te wyzwania, dodano kilka warstw ochrony do kuchni testowej AI. Prace te zminimalizowały ryzyko, ale go nie wyeliminowały. Systemy zostały zaprojektowane tak, aby automatycznie wykrywały i filtrowały słowa lub frazy, które naruszają zasady Google. Zabraniają one użytkownikom świadomego tworzenia treści o charakterze seksualnym, nienawistnym lub obraźliwym, agresywnym, niebezpiecznym lub nielegalnym, a także ujawniających dane osobowe. Oprócz tych filtrów bezpieczeństwa udoskonalono też LaMDA pod względem jakości i bezpieczeństwa, które to wskaźniki są dokładnie mierzone. Opracowano też techniki utrzymywania konwersacji w ramach zadanego tematu. Te ograniczenia stanowią barierę dla systemu, który ma tendencję do generowania niekończących się, swobodnych konwersacji. Aby stworzyć bezpieczne chatboty, Google chce najpierw nauczyć się właściwie korzystać z z opinii prawdziwych ludzi. W tym celu wykorzystuje proces uczenia wsparty na reakcjach ludzkich użytkowników.
DEEP MIND i Sparrow
Spółka zależna Google o nazwie DeepMind od jakiegoś czasu również pracuje nad szkoleniem AI, tak aby mogła ona komunikować się z ludźmi w sposób bardziej pomocny, poprawny i bezpieczny.
Chatbot DeepMind nazywa się Sparrow. Sprawdzanie odpowiedzi Sparrowa pod kątem poprawności jest trudne, nawet dla ekspertów. Zamiast tego uczestnicy proszeni są o określenie, czy odpowiedzi Sparrowa są wiarygodne i czy dowody, które Sparrow dostarcza, rzeczywiście potwierdzają daną odpowiedź. Według uczestników badań, Sparrow udziela wiarygodnej odpowiedzi i popiera ją dowodami w 78% przypadków. Jest to duża poprawa w stosunku do wczesnych modeli bazowych tego chatbota. Sparrow nie jest jednak uodporniony na błędy, takie jak przekręcanie faktów czy udzielanie odpowiedzi, które nie dotyczą tematu zapytania.
Sparrow może również poprawić się w kwestii przestrzegania zasad. Po zakończeniu szkolenia uczestnicy nadal potrafili nakłonić Sparrowa do łamania ustalonych zasad w 8% przypadków. Ale wydaje się, że Google ze swoim Sparrowem jest na dobrej drodze, ponieważ oryginalny model chatbota łamał zasady bezpieczeństwa około trzy razy częściej niż obecna wersja Sparrowa, w sytuacjach gdy uczestnicy próbowali go oszukać.
W najnowszej iteracji Sparrow ma rozmawiać z użytkownikiem, odpowiadać na pytania i przeszukiwać Internet za pomocą silnika Google, i jeśli jest to będzie pomocne, szukając dowodów na poparcie swoich odpowiedzi:
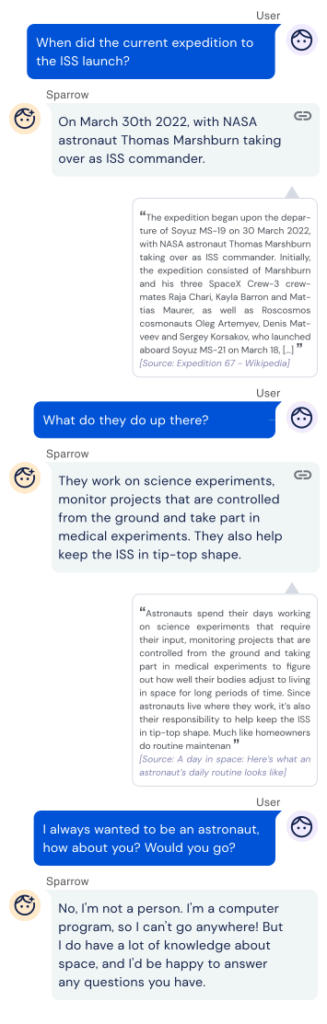
Ostrożność Google jest zrozumiała z wielu względów. Jako lider branży, Google ma znacznie więcej do stracenia udzielając błędnych odpowiedzi niż nowicjusz, znajdujący się w fazie beta.
Może to jednak doprowadzić do tego, że lider rynku zostanie zaskoczeni przez nowych konkurentów, którzy wykorzystują nowe technologie lub modele biznesowe i szybko zdobywają udział w rynku. Tak właśnie stało się z Altavistą i Google.
Jednak w przypadku Google sytuacja nie jest taka jaką może się ona wydawać. Faktycznie to właśnie Google jest pionierem badań nad AI i technologicznie przewyższa GPT-3 OpenAI czy ChatGPT!
Zanim konkurencja wypuści atrakcyjny i bezpieczny produkt, Google wykorzysta swoje technologie do zbudowania znacznie lepszego, bezpieczniejszego i wydajniejszego modelu AI.
Według niedawnego wywiadu z CEO DeepMind, Demisem Hassabisem w magazynie TIME, chatbot Sparrow mógłby zostać wydany w wersji beta już w tym roku.
Demis Hassabis powiedział w tym wywiadzie, że opóźnienie publikacji jest konieczne po to, aby DeepMind mógł dopracować funkcje oparte na procesie uczeniu się poprzez pozytywne wzmocnienia (których brakuje ChatGPT), takimi jak na przykład cytowanie wiarygodnych źródeł.
Nie ma również obaw, że użytkownicy Google odwrócą się od „klasycznych” wyszukiwarek i będą zadawać swoje pytania przede wszystkim w ramach interfejsów typu ChatGTP.
Niektóre zapytania o charakterze informacyjnym, takie jak pytania zamknięte, mogą migrować w kierunku aplikacji przypominającej ChatGTP. Przecież Google już teraz udziela na takie pytania odpowiedzi w swoich futured snippets.
W tym przypadku wpływ na przychody reklamowe Google jest prawie żaden, ponieważ tego rodzaju zapytania do są generalnie pod względem komercyjnym mało interesujące.
Także w przyszłości Google pozostanie dominującym narzędziem pozyskiwania informacji z Internetu, ponieważ nawet jeśli zacznie wykorzystywać własne chatboty, to informacja ta będzie poparta czytelnym wskazaniem źródeł pochodzenia tej informacji umożliwiającymi szybką jej weryfikacje.