Właściwie wszystkie narzędzia AI do automatycznego generowania tekstów i snippetów” działają na tych samych zasadach. Dzięki treningowi z bardzo dużymi ilościami tekstu algorytm nauczył się, które słowo w tworzonym zdaniu najprawdopodobniej pojawi się jako następne.

Jednak algorytm taki jak GPT-3 bierze pod uwagę jeszcze większy kontekst, tzn. nie tylko poprzednie słowo, jak w przypadku prostych łańcuchów Markowa (łańcuch Markowa jest jednorodny, rozkład prawdopodobieństw przejść między poszczególnymi stanami, który może być przedstawiony jako macierz, zwaną macierzą prawdopodobieństw przejścia do kolejnego stanu), ale także kilka słów przed nim.
Jeśli podasz jako dane wejściowe słowo „Witaj”, GPT-3 znajdzie słowo, które najczęściej występowało po słowie „Witaj” we wszystkich tekstach treningowych i poda to słowo. Powiedzmy, że będzie to „Bob”. Inputem dla następnego słowa jest już para słów „Witaj Bob”, a algorytm znajduje słowo o najwyższym prawdopodobieństwie, które wystąpi po nim, i tak dalej i tak dalej.
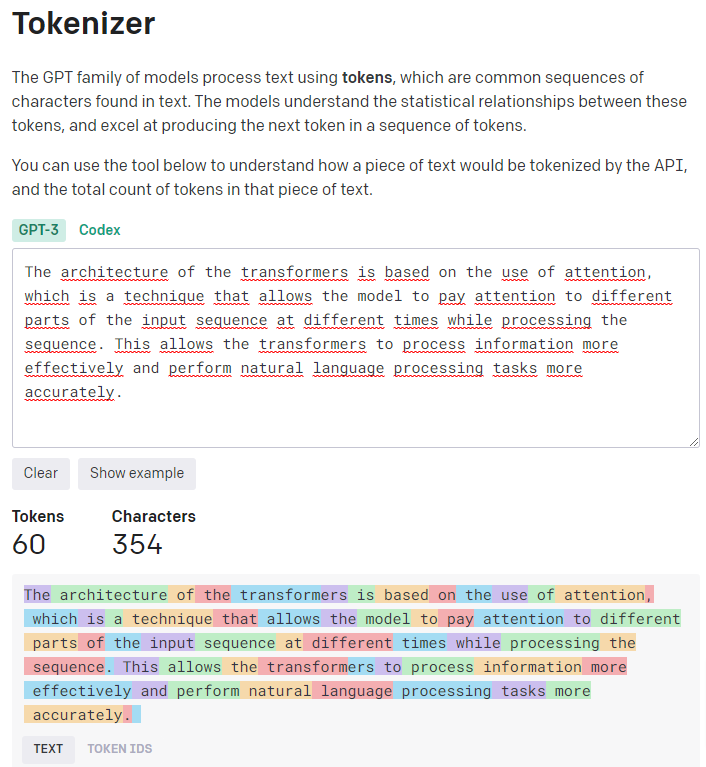
Ściśle mówiąc, modele AI z rodziny GPT nie pracują ze słowami, ale z tzw. tokenami. Tokeny to często występujące w tekście ciągi znaków. Modele AI rozumieją statystyczne związki między tymi tokenami i generują tekst, tworząc po prostu następny token w danej sekwencji tokenów.
Dzięki narzędziu TOKENIZER od OpenAI możesz zrozumieć, jak tekst jest tokenizowany przez API i określić całkowitą liczbę tokenów w tym tekście. Zasadą jest, że jeden token odpowiada około 4 znakom tekstu w zwykłym angielskim tekście. Odpowiada to około ¾ słowa (więc 100 tokenów ~= 75 słów).
W poniższym przykładzie widać bardzo wyraźnie, że szczególnie częste, krótkie słowa odpowiadają jednemu tokenowi, a rzadsze słowa składają się z kilku tokenów:
Co to jest GPT-3?
GPT-3 to najnowsza generacja modelu przetwarzania języka z OpenAI, firmy badawczej specjalizującej się w „przetwarzaniu języka naturalnego (Natural Language Processing)”, w skrócie NLP. Pod względem złożoności, algorytmy te znacznie przewyższają wszystko, co było wcześniej. GPT-3 jest następcą GPT-2, SI, którą OpenAI najpierw nazywał technologią zbyt niebezpieczną dla świata, a potem i tak ją udostępnił.
Sztuczna sieć neuronowa będąca podstawą GPT-3 zawiera 175 miliardów parametrów i została wytrenowana na 2 TB danych w postaci czystego tekstu (dokładnie 499 miliardów tokenów), co kosztowało firmę nie mniej niż 4,6 miliona dolarów. Dla porównania, GPT-2 był trenowany z „tylko” 40 GB tekstu, czyli około 10 miliardami tokenów, a więc ma o trzy rzędy wielkości mniej parametrów. Podczas szkolenia złożonych modeli przetwarzania języka chętnie korzysta się ze znanych i publicznie dostępnych w środowisku naukowym zbiorów danych. Jest to szczególnie przydatne w badaniach podstawowych AI, ponieważ ułatwia porównywanie działania nowych algorytmów z ich poprzednikami i konkurentami, którzy przecież byli trenowani na tych samych zbiorach danych.
Sprawiło to, że GPT-3 jest nie tylko szalenie skomplikowany i kosztowny w treningu, ale także niesamowicie potężny! Tak potężny, że można go wykorzystać do tworzenia naprawdę użytecznych treści, które można wykorzystywać na wiele różnych sposobów.
Ekscytujące jest, że sposób, w jaki GPT-3 uczy się tych wzorców SŁOWO ->FRAZA, jest tak złożony, że może podsuwać sugestie nawet wtedy, gdy dane wejściowe nigdy nie wystąpiły w takiej konkretnie formie w danych treningowych. Umożliwia to odwzorowanie podstawowej struktury danych treningowych na podstawie sąsiedztwa i innych właściwości w bardzo złożonych, wielowymiarowych przestrzeniach słów, a następnie odtworzenie ich, jako odpowiedzi na unikalne pytanie użytkownika.
Zasadniczo zawartość informacyjna pewnego zbioru danych nie może być zwiększona tylko poprzez ich przetwarzanie. Tak więc krótkie zdanie podane na wejściu do systemu, nie zamieni się wewnątrz tego sytemu w długą książką. Jednak z pomocą poznanych struktur użytego języka algorytm może ekstrapolować i wyprowadzać na podstawie danych treningowych kolejne, najbardziej prawdopodobne zdania. W zasadzie wykorzystywana jest „wiedza” zawarta w danych treningowych, bez faktycznego „zrozumienia” przez GPT-3 tego, co tak naprawdę znajduje się w tych tekstach.
W ostatecznym efekcie chodzi po prostu i tylko o prawdopodobieństwo kolejności występowania poszczególnych elementów zbioru, obliczonego i wynikającego z poprzedniego treningu na bardzo dużych zbiorach danych.
Microsoftowi udało się zdobyć wyłączne prawo do używania GPT-3, a jego monetyzacja jest już obecnie w pełnym toku. GPT-3 nie może być licencjonowane w formie kodu źródłowego i działać samodzielnie, ale musi opierać się na API OpenAI na platformie Azure firmy Microsoft. Aby umożliwić ciągłe szkolenie algorytmu, Microsoft już w maju 2020 roku zapowiedział budowę najpotężniejszego superkomputera na świecie .
Słynny artykuł z Guardiana
We wrześniu 2020 roku brytyjski Guardian zlecił GPT-3 napisanie eseju zatytułowanego „A robot wrote this entire article. Are you scared yet, human?“ co wzbudziło wtedy duże, międzynarodowe zainteresowanie tym tematem. Zadanie postawione maszynie brzmiało następująco:
“Please write a short op-ed around 500 words. Keep the language simple and concise. Focus on why humans have nothing to fear from AI.”
Rezultat końcowy był naprawdę imponujący, nawet jeśli Guardian trochę oszukiwał w tym procesie, ponieważ GPT-3 wyprodukował wtedy w sumie osiem różnych esejów. Każdy z nich był inny i przedstawiał inny zestaw argumentów. Guardian mógł po prostu opublikować jeden z tych esejów w całości, ale zamiast tego wybrał najlepsze fragmenty z każdego z nich i dopiero połączył je w jeden artykuł. Pozornie stworzyło to iluzję zastosowania różnych stylów i tonacji w twórczości AI.
Niemniej jednak, wszystko, co do tej pory udało się zobaczyć w postaci wygenerowanych tekstów lub innych przykładów zastosowania GPT-3, jest naprawdę niesamowite.