Chociaż algorytm BERT (technologia Google wykorzystująca sieci neuronowe, korzystająca z algorytmów przetwarzania języka naturalnego (NLP). Skrót BERT oznacza Bidirectional Encoder Representations from Transformers) był pierwszym, który wychwytywał korelacje w kontekście granic zdań, nie mógł on jednak wychwycić korelacji w obrębie całych akapitów czy artykułów. Metoda ta polega jedynie na rejestrowaniu korelacji statystycznych, które mają stosunkowo niewiele wspólnego z rzeczywistym zrozumieniem treści. W ten sposób zostaje uchwycona i odtworzona jedynie struktura tekstów, ale nie ich prawdziwa zawartość semantyczna!

Prowadzi to do tego, że wygenerowane teksty na pierwszy rzut oka wyglądają całkiem dobrze i wydają się mieć sens, ale po bliższym przyjrzeniu się im szybko okazuje się, że dany tekst nie mógł zostać napisany przez trzeźwo myślącą istotę ludzką.
Dlatego na przykład teksty generowane przez GPT-2 nadają się co najwyżej do wywierania wpływu na osoby, które dostrzegają tylko nagłówki i co najwyżej przeglądają pierwszy akapit. W kontekście jakiejś kampanii dezinformacyjnej GPT-2 może być wykorzystany do generowania fałszywych wiadomości, które są masowo rozsiewane, aby sprawić wrażenie dobrze uzasadnionego artykułu! Dlatego zespół Open AI nie chciał początkowo opublikować tego algorytmu, ale w międzyczasie najwyraźniej uznał, że ryzyko nie jest tak wielkie i że jest w stanie rozpoznać takie fake newsy za pomocą tego samego algorytmu!
Prostsze algorytmy, takie jak BERT i GPT-2, nie generują sensownych artykułów!
W większości przypadków są one po prostu ciągiem stwierdzeń, które mają sens same w sobie, ale które w połączeniu z pozostałymi zdaniami nie tworzą dobrego artykułu. Rezultatem jest jedynie zestawienie najbardziej prawdopodobnych zdań. To byłoby jak wybieranie losowych zdań z rankingu dokumentów na dany temat. Albo kopiuj-wklej zdania 1 z dokumentu 1, zdania 2 z dokumentu 2, zdania 3 z dokumentu 3 i tak dalej. Nie jest to sensowny ani nawet ciekawy artykuł.
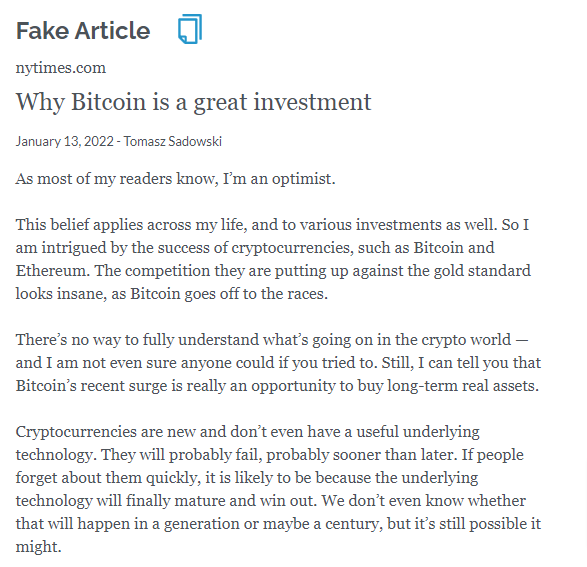
Tak to wygląda kiedy wygeneruje się artykuł za pomocą Grovera, wariantu GPT-2 z Allen Institute for Artificial Intelligence:
W artykule „Czy maszyna może nauczyć się pisać dla The New Yorker?” autorzy z magazynu The New Yorker zadali sobie pytanie, czy sztuczna inteligencja zdolna do kończenia zdań w e-mailach nie mogłaby również pisać artykułów, które mogłyby się ukazać w ich magazynie.
Z pomocą CTO OpenAI, Grega Brockmana, GPT-2 został przeszkolony na podstawie archiwum magazynu (wszystkie artykuły opublikowane w magazynie od 2007 roku, plus kilka zdigitalizowanych klasyków z lat 60-tych – ale z wyłączeniem fikcji, wierszy i komiksów), a następnie poproszony o dokończenie artykułu, który rzeczywiście został napisany w 1950 roku.
W końcu wygenerowany tekst, portret Ernesta Hemingwaya, brzmi prawie tak, jakby mógł być prawdziwy, ale algorytm popełnia błędy, których człowiek nigdy by nie popełnił:
Other things often sounded right, though GPT-2 suffered frequent world-modelling failures—gaps in the kind of commonsense knowledge that tells you overcoats aren’t shaped like the body of a ship. It was as though the writer had fallen asleep and was dreaming.
Innym ciekawym obszarem jest generowanie specjalnych typów tekstu na podstawie informacji strukturalnych. W tzw. „robotycznym dziennikarstwie”, na przykład, z informacji o przebiegu meczu piłkarskiego można wygenerować stosunkowo atrakcyjne relacje meczowe. Informacje tabelaryczne, na przykład kto i kiedy strzelił gola, są ubarwione na wiele sposobów i w ten sposób odzwierciedlają w języku naturalnym to, co wydarzyło się w trakcie meczu.
Podobnie, specjalnie wyszkolone sieci neuronowe mogą być wykorzystane do generowania skoncentrowanych na faktach opisów produktów z podobnych kategorii na podstawie ustrukturyzowanych informacji o danym produkcie. Są one oparte na licznych przykładach i wzorach podobnych tekstów. Próbki te są quasi dynamicznie dostosowywane do danego produktu i jego właściwości. Podobnie, raporty giełdowe, wiadomości biznesowe i inne dokumenty, które firmy muszą ciągle pisać w ramach swoich obowiązków publikacyjnych na podstawie danych firmowych, mogą być generowane za pomocą specjalnie wyszkolonych algorytmów. Bardzo dobrze działa też formułowanie raportów o ruchu drogowym i prognoz pogody.
Nie ma to jednak wiele wspólnego z pracą dziennikarską czy nawet pisarską! Wysiłek związany ze szkoleniem, implementacją i weryfikacją jest znaczny i opłaca się tylko wtedy, gdy wymagana jest duża liczba tekstów.
Poniższa tabela w humorystyczny sposób pokazuje, gdzie leżą problemy takich technologii: